Apple ha introdotto SlowFast-LLaVA-1.5, una nuova famiglia di modelli video in linguaggio di grandi dimensioni (Video-LLM) progettati per comprendere in modo efficiente i video di lunga durata. Nel suo documento di ricerca, Apple spiega che la maggior parte dei LLM video esistenti lotta con elevati costi computazionali e un utilizzo eccessivo di token durante l’analisi di contenuti video estesi, il che limita la loro capacità di scalabilità. SlowFast-LLaVA-1.5 risolve questo problema introducendo un framework efficiente in termini di token che riduce il numero di token necessari per rappresentare il video mantenendo la precisione.
L'efficienza dei token è fondamentale perché ogni fotogramma di un video deve essere convertito in token prima che un LLM possa elaborarlo. Con i video di lunga durata, il numero di token diventa rapidamente ingestibile, facendo aumentare i costi e rallentando le prestazioni. L’approccio di Apple comprime i dati video in modo da utilizzare meno token senza perdere il contesto importante. Combinando questo con un’architettura a doppio percorso, in cui un percorso “lento” cattura modelli a lungo termine e un percorso “veloce” si concentra su dettagli a breve termine, il modello può bilanciare comprensione ed efficienza. Ciò gli consente di tracciare sia le trame generali che le azioni dettagliate attraverso sequenze estese.
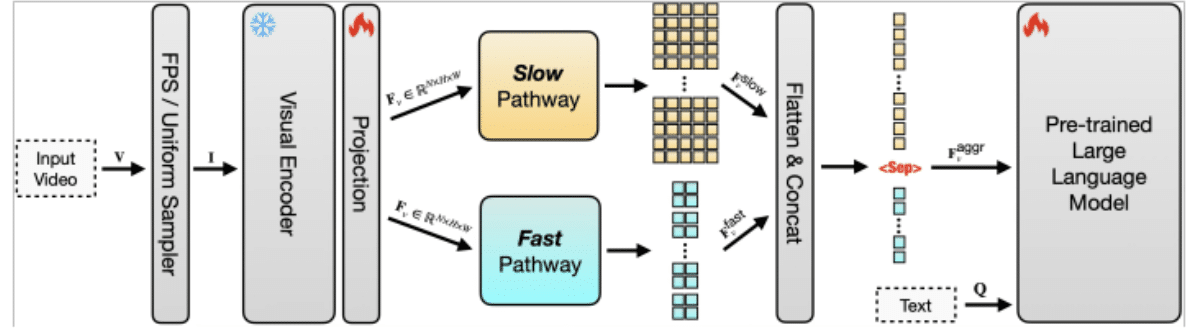
Il sistema è anche altamente scalabile, il che significa che può espandersi per gestire video molto più lunghi e set di dati più grandi senza sovraccaricare le risorse di elaborazione. I modelli tradizionali diventano poco pratici con l’aumentare della lunghezza dell’input, ma il design di Apple garantisce che il passaggio da clip brevi a filmati di più ore rimanga fattibile. Ciò rende SlowFast-LLaVA-1.5 adatto per attività quali la risposta a domande video, il ragionamento temporale, il riepilogo e il recupero di contenuti in archivi video lunghi.
Nei test benchmark, Apple riferisce che il modello ottiene ottimi risultati su set di dati come Video-MME e LongVideoBench, mostrando sia efficienza che comprensione migliorate rispetto agli approcci precedenti. La ricerca introduce anche diverse dimensioni del modello, comprese le versioni dei parametri 1.5B, 7B e 13B, che sono ottimizzate con istruzioni per seguire le istruzioni del linguaggio naturale. Ciò consente al sistema di generare risposte dettagliate su contenuti video complessi, rendendolo applicabile per l'analisi di video didattici, il riepilogo delle riunioni e strumenti di accessibilità che creano didascalie o trascrizioni ricercabili.
Per saperne di più:TikTok abbraccia contenuti di lunga durata con caricamenti video di 60 minuti
Apple sottolinea che il design efficiente e scalabile in termini di token non riguarda solo la novità della ricerca ma anche la praticità. Riducendo i requisiti computazionali e ampliando al tempo stesso le capacità, il modello apre la strada all'integrazione della comprensione dei video di lunga durata nei prodotti del mondo reale. Mentre il video continua a dominare l’intrattenimento, l’istruzione e la comunicazione professionale, il video LLM di lunga durata di Apple rappresenta un passo significativo verso un’intelligenza artificiale multimodale avanzata utilizzabile e accessibile.
Consulta il documento completoQui.