A Apple lançou o SlowFast-LLaVA-1.5, uma nova família de modelos de vídeo em linguagem grande (Video-LLMs) projetados para compreender com eficiência vídeos de formato longo. Em seu artigo de pesquisa, a Apple explica que a maioria dos LLMs de vídeo existentes lutam com altos custos computacionais e uso excessivo de tokens ao analisar conteúdo de vídeo estendido, o que limita sua capacidade de escala. SlowFast-LLaVA-1.5 resolve isso introduzindo uma estrutura com eficiência de tokens que reduz o número de tokens necessários para representar o vídeo, mantendo a precisão.
A eficiência do token é crítica porque cada quadro de um vídeo deve ser convertido em tokens antes que um LLM possa processá-lo. Com vídeos de formato longo, o número de tokens rapidamente se torna incontrolável, aumentando os custos e diminuindo o desempenho. A abordagem da Apple compacta dados de vídeo para que menos tokens sejam usados sem perder contexto importante. Ao combinar isto com uma arquitetura de via dupla, onde uma via “lenta” captura padrões de longo prazo e uma via “rápida” se concentra em detalhes de curto prazo, o modelo pode equilibrar compreensão com eficiência. Isso permite rastrear enredos abrangentes e ações refinadas em sequências estendidas.
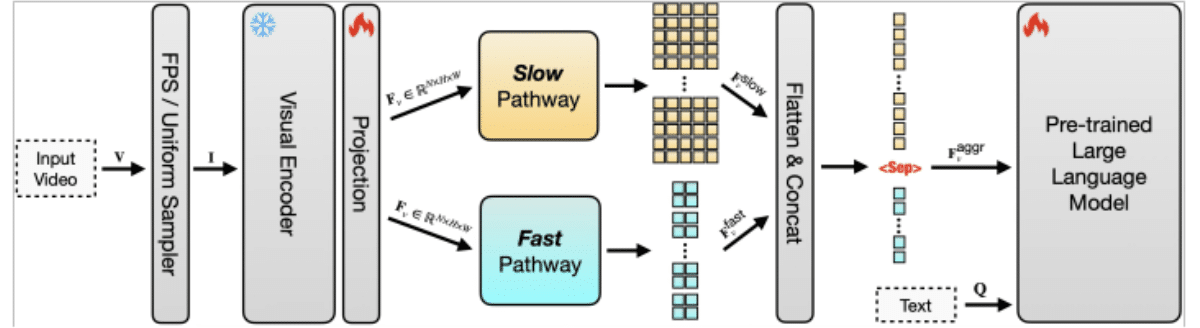
O sistema também é altamente escalável, o que significa que pode ser expandido para lidar com vídeos muito mais longos e conjuntos de dados maiores sem sobrecarregar os recursos de computação. Os modelos tradicionais tornam-se impraticáveis à medida que a duração da entrada aumenta, mas o design da Apple garante que a escala de clipes curtos para filmagens de várias horas permaneça viável. Isso torna o SlowFast-LLaVA-1.5 adequado para tarefas como resposta a perguntas de vídeo, raciocínio temporal, resumo e recuperação de conteúdo em longos arquivos de vídeo.
Em testes de benchmark, a Apple relata que o modelo alcança resultados sólidos em conjuntos de dados como Video-MME e LongVideoBench, mostrando maior eficiência e compreensão em comparação com abordagens anteriores. A pesquisa também apresenta vários tamanhos de modelo, incluindo versões de parâmetros de 1,5B, 7B e 13B, que são ajustadas por instrução para seguir instruções de linguagem natural. Isso permite que o sistema gere respostas detalhadas sobre conteúdo de vídeo complexo, tornando-o aplicável para análise de vídeos educacionais, resumo de reuniões e ferramentas de acessibilidade que criam legendas ou transcrições pesquisáveis.
Leia mais:TikTok adota conteúdo longo com uploads de vídeos de 60 minutos
A Apple enfatiza que o design escalonável e eficiente em termos de tokens não se trata apenas de novidade em pesquisa, mas também de praticidade. Ao reduzir os requisitos computacionais e ao mesmo tempo expandir a capacidade, o modelo abre caminho para a integração da compreensão de vídeo de formato longo em produtos do mundo real. À medida que o vídeo continua a dominar o entretenimento, a educação e a comunicação profissional, o LLM de vídeo de formato longo da Apple representa um passo significativo para tornar a IA multimodal avançada utilizável e acessível.
Confira o artigo completoaqui.